UPDATE (later in the day): I really didn’t want to give the site any clicks but it looks like they do come clean about what it is on the Contributors page. And, there clearly is a business case (especially if you believe the ”## of ### left”). I now completely stand by the ‘Close the issue. Don’t add the badge.’ advice at the end of this piece.
Something felt off about the issue the moment I saw it. A GitHub account called basicScandal had opened #38 on hrbrmstr/pewpew with the kind of breathless enthusiasm that typically signals either a very enthusiastic user or someone who’s never actually run the tool. “We recently came across your project and were impressed enough to write a deep-dive article about it on Starlog.” A link. A badge. An opt-out notice. I’d never heard of Starlog. That’s usually where I’d close the tab, but the opt-out notice snagged my attention – you don’t include an opt-out notice if you expect the target to be delighted.
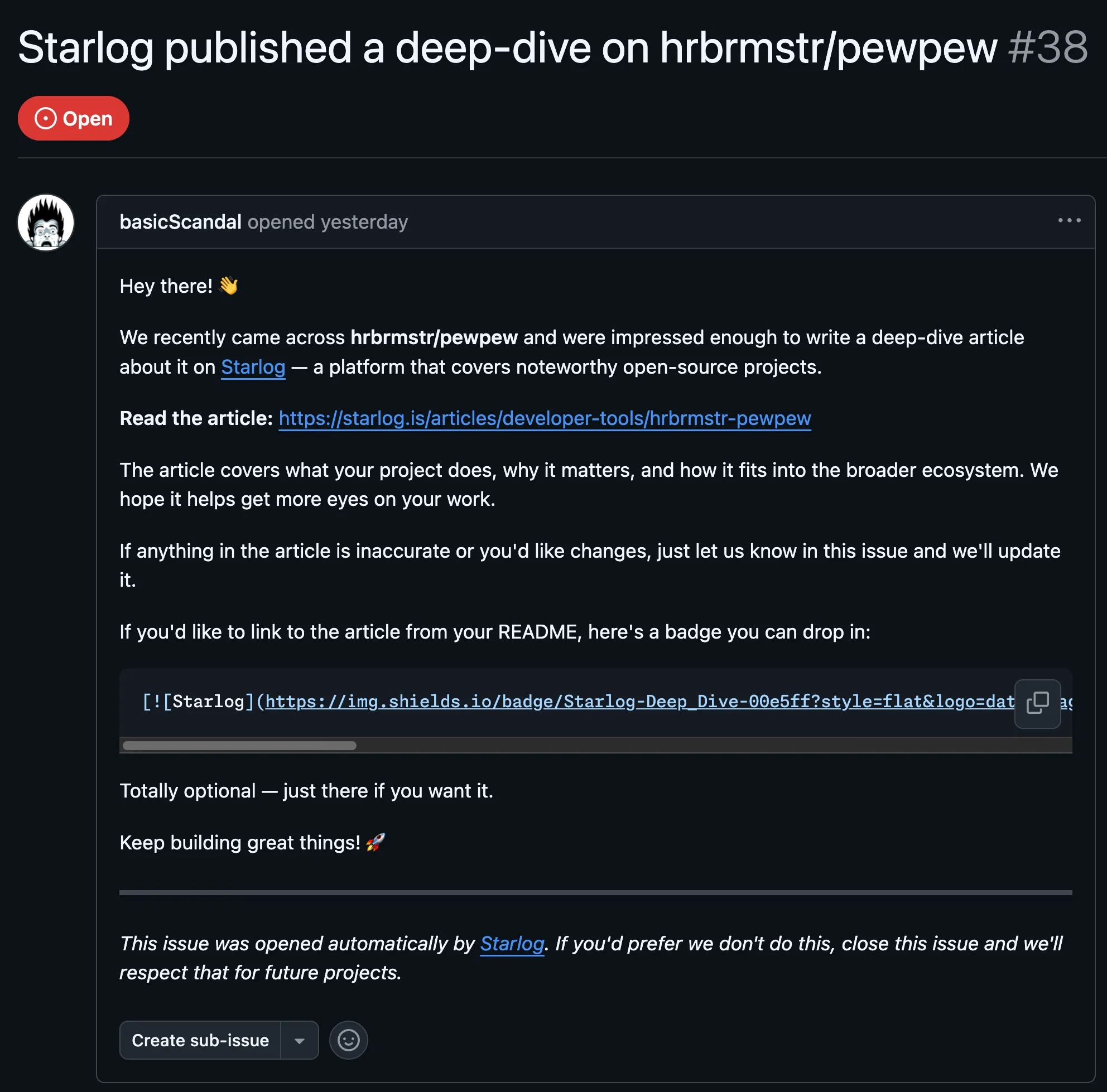
So I searched GitHub for “Starlog published” in issues. The results page showed 383 of them (as of this blog post).
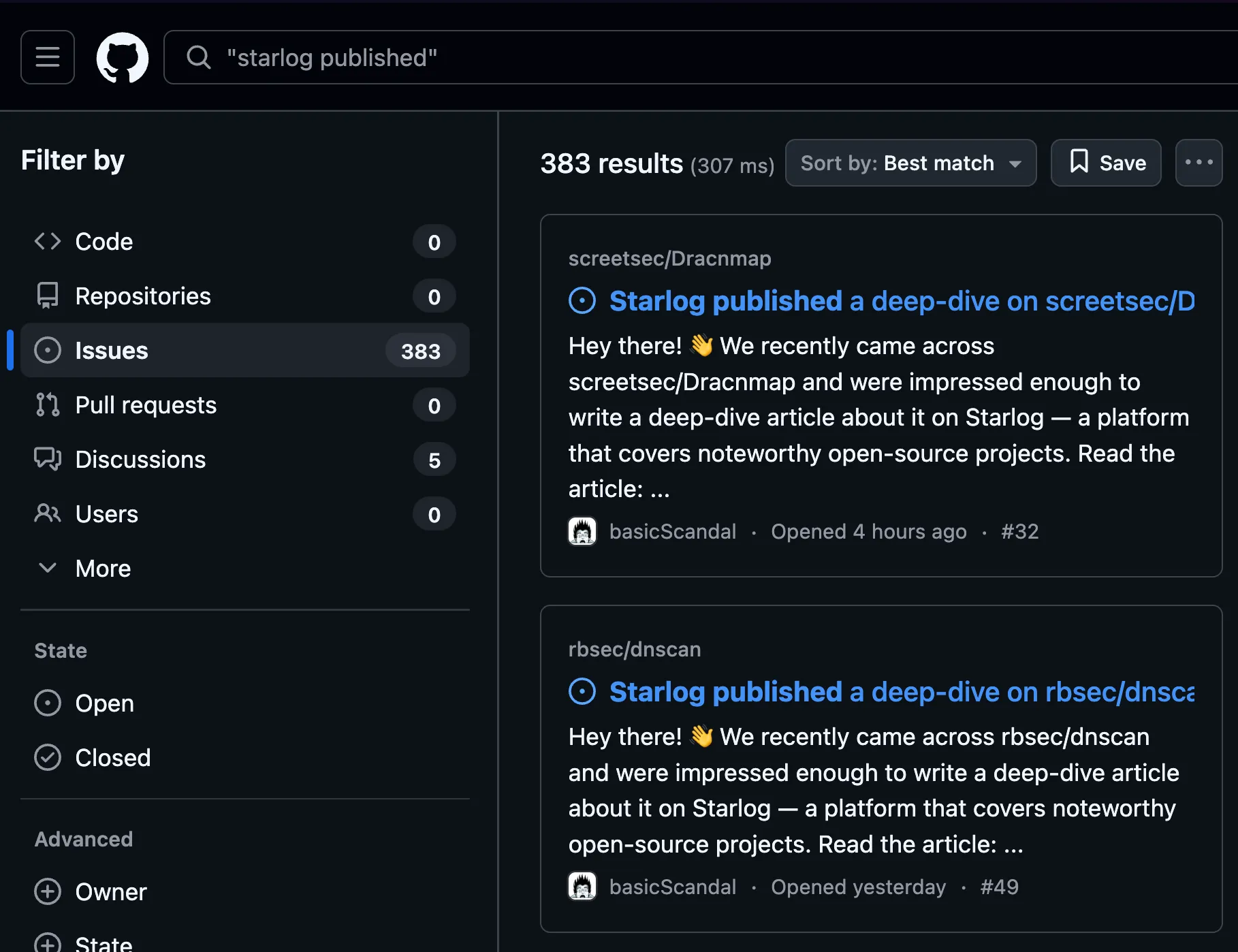
That number changes the story considerably. One enthusiastic fan writing about your project is… flattering? 383 automated issues opened over five days – peaking at 186 in a single day on April 3rd – is a campaign. A well-targeted one, at that. The repos being hit weren’t random: the star distribution skewed toward the 100–4,999 range (121 repos in the 100–499 bucket alone), with a median of 195 stars, which is roughly “real project with real users” territory. Someone had thought about what makes a repo worth covering.
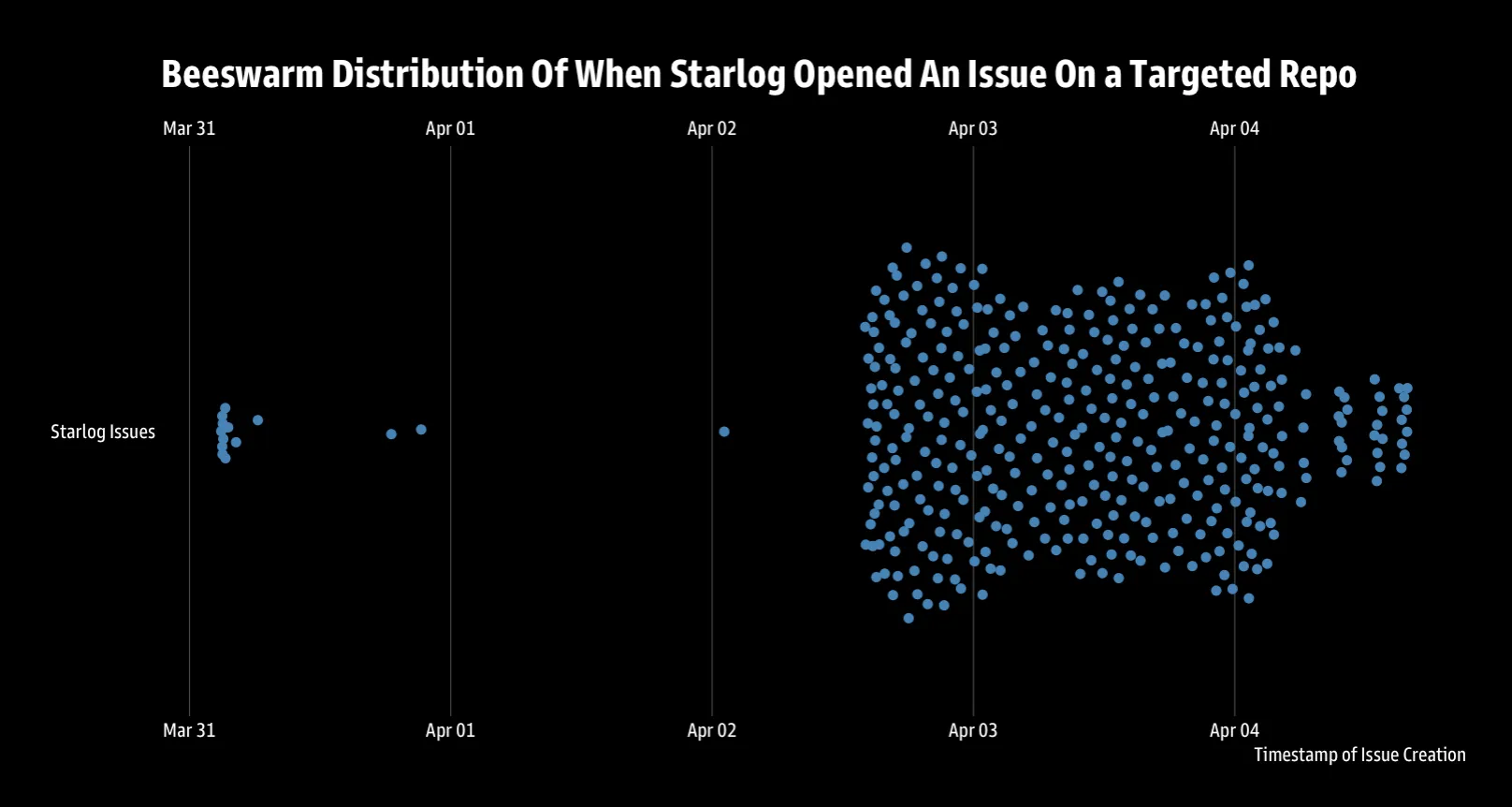
I spent some time with Claude Code (fighting AI fire with AI fire, and all that) building a tracker to pull and analyze the full picture, and the targeting profile is genuinely interesting. Of the 379 unique repos hit, 168 fell under “developer-tools” and 82 under “cybersecurity”—which together account for more than 65% of the campaign. The top topics across targeted repos read like a bug bounty conference schedule: security, pentesting, bugbounty, hacking, exploit, and OSINT. Someone is specifically interested in the infosec community’s attention. Though the classification logic has visible seams: one of my other repos, cloudcidrs—an R package for resolving cloud provider IP ranges—got filed under “ai-dev-tools.” The article may still be accurate; the category is not. The pipeline that reads the code and the pipeline that assigns the taxonomy are clearly not comparing notes.
The articles themselves aren’t garbage, which complicates the easy dismissal. Every piece on Starlog follows an identical five-section structure: Hook, Context, Technical Insight, Gotcha, Verdict. The Gotcha section is where it gets interesting – it’s genuinely honest about limitations in a way that most human-written promotional content isn’t. The Verdict gives explicit “Use if / Skip if” guidance. These are substantive, not keyword-stuffed SEO slop. The analysis matched the actual repos: real star counts, real languages, real architectural patterns pulled from the code. The article about Dracnmap correctly identified it as a menu-driven nmap wrapper and accurately described its learning-by-doing value proposition. That’s not a hallucination, that’s a pipeline that actually read the repo.
Which is where the business model interrogation starts. All the articles fetched so far were clearly generated in a batch. All carry the byline “By Rob Ragan” with a star count and language tag. The articles require JavaScript rendering to load, meaning the content isn’t being indexed easily by competitors. And then there’s the badge: a shields.io badge you’re invited to drop into your README, pointing back to starlog.is, which is functionally a backlink campaign disguised as community recognition. The “business” model here isn’t hard to see – build domain authority through genuine-looking content, get repo maintainers to voluntarily embed outbound links in high-traffic READMEs, watch the SEO numbers climb. Let’s call it a citation network dressed as a fan site.
The cybersecurity angle is worth dwelling on. Of the repos targeted, 26 closed the issue immediately (about 7% close rate), but 357 are still open. The infosec community has developed reasonable spam intuitions, but a message that says “we wrote a deep-dive about your tool” creates a genuinely interesting cognitive trap: if someone did write an accurate article about your project, is suppressing it the right move? Most maintainers are going to click through. Some are going to be genuinely flattered. The content quality is high enough that the opt-out notice might read as courtesy rather than warning.
There’s an irony worth dwelling on: none of the Starlog articles say “this was generated by an AI.” The byline is “Rob Ragan”—a real security community-recognized identity being used to front AI-generated content targeting that same security community. For a community that builds tools to detect, analyze, and defend against automated threats, there’s a particular irony in being on the receiving end of an automated content campaign that’s harder to dismiss because it’s technically accurate. The articles aren’t claiming your tool does things it doesn’t. They’re not defaming anyone. They’re just… generated, at scale, without asking.
Whether that rises to “harm” is genuinely unclear to me. It’s “spam” by any reasonable definition – 383 unsolicited issues from a single account in five days, with a possible commercial motive (dervied via the “partner inquiries” in the footer). But the content of the articles is defensible on its merits, the opt-out is real (closing the issue does appear to suppress future targeting), and the characterizations are accurate. It’s the ambiguity that’s interesting. This is what happens when LLM-generated content is good enough to require actual analysis before you can dismiss it. The days of “obviously AI slop” as a sufficient rebuttal are numbered. What we’ve got here is a dress rehearsal for the kind of automated, targeted, technically-accurate content campaigns that are going to get a lot harder to classify cleanly as spam.
Close the issue. Don’t add the badge. But do think about what you’d say if someone asked you to prove this is wrong.
If you want to look at the stats yourself there’s a DuckDB database available for download”
🦆>.schema
CREATE TABLE articles(article_url VARCHAR PRIMARY KEY, title VARCHAR, "content" VARCHAR, fetched_at TIMESTAMP DEFAULT(current_timestamp));
CREATE TABLE issues(issue_url VARCHAR PRIMARY KEY, repo_owner VARCHAR NOT NULL, repo_name VARCHAR NOT NULL, repo_full_name VARCHAR NOT NULL, issue_title VARCHAR, issue_number INTEGER, issue_state VARCHAR, article_url VARCHAR, article_category VARCHAR, author VARCHAR, created_at TIMESTAMP, collected_at TIMESTAMP DEFAULT(current_timestamp));
CREATE TABLE poll_log(poll_id INTEGER DEFAULT(nextval('poll_seq')) PRIMARY KEY, polled_at TIMESTAMP DEFAULT(current_timestamp), new_issues_found INTEGER, total_issues INTEGER);
CREATE TABLE repos(repo_full_name VARCHAR PRIMARY KEY, stars INTEGER, "language" VARCHAR, topics VARCHAR[], description VARCHAR, created_at TIMESTAMP, pushed_at TIMESTAMP, archived BOOLEAN, fork BOOLEAN, forks_count INTEGER, open_issues_count INTEGER, license VARCHAR, collected_at TIMESTAMP DEFAULT(current_timestamp));