2026-05-27 Case Update: The empty RSS file now has entries again. Just a glitch then? We’ll never know unless the LLMs writing the site content fess up during a bit flip.
This is the fourth post in the Starlog series, following “Starlog And The Case Of The Missing ‘LLM’ Tag”, “Starlog And The Case Of The Missing Issues And Owner”, and “The [GitHub] Stars Are Better Off Without Us”.
A month went by. I figured the story was done — the GitHub issues scrubbed, the basicScandal account deleted, the posting pace dropped to something a human could plausibly maintain. Zero new entries in the Inoreader Starlog section in quite a while. Case closed, lessons noted, move on.
Then I decided to check the RSS feed myself, since you can’t trust the Clankers:
<rss version="2.0">
<channel>
<title>Starlog — Offsec & AI Agent Intel</title>
<description>Expert-curated deep-dives on offensive security tools
and AI agents. By Rob Ragan.</description>
<link>https://starlog.is/</link>
</channel>
</rss>That’s the entire feed. An RSS document with a title, a description, and nothing else. No items. No entries. No content. The shell of a syndication format with the syndication removed. “Expert-curated” is doing a lot of heavy lifting in that description tag for a site that has never involved a human expert curator at any point in its documented history.
The feed didn’t break. It was emptied. Deliberately. Someone decided that the easiest way to stop external monitoring of their publication activity was to serve a valid RSS document containing no publications. Technically compliant. Functionally opaque.
They also rewrote the publication dates. Every article on the site now carries a timestamp from May 2026 — the historical record of when repos were originally scraped and processed has been overwritten. The batch-processing fingerprint documented in April, the one that showed hundreds of articles generated in tight temporal clusters, has been laundered into a different distribution. If you weren’t watching before, you’d never know.
Here’s what the current publication pattern looks like with minute-level resolution:
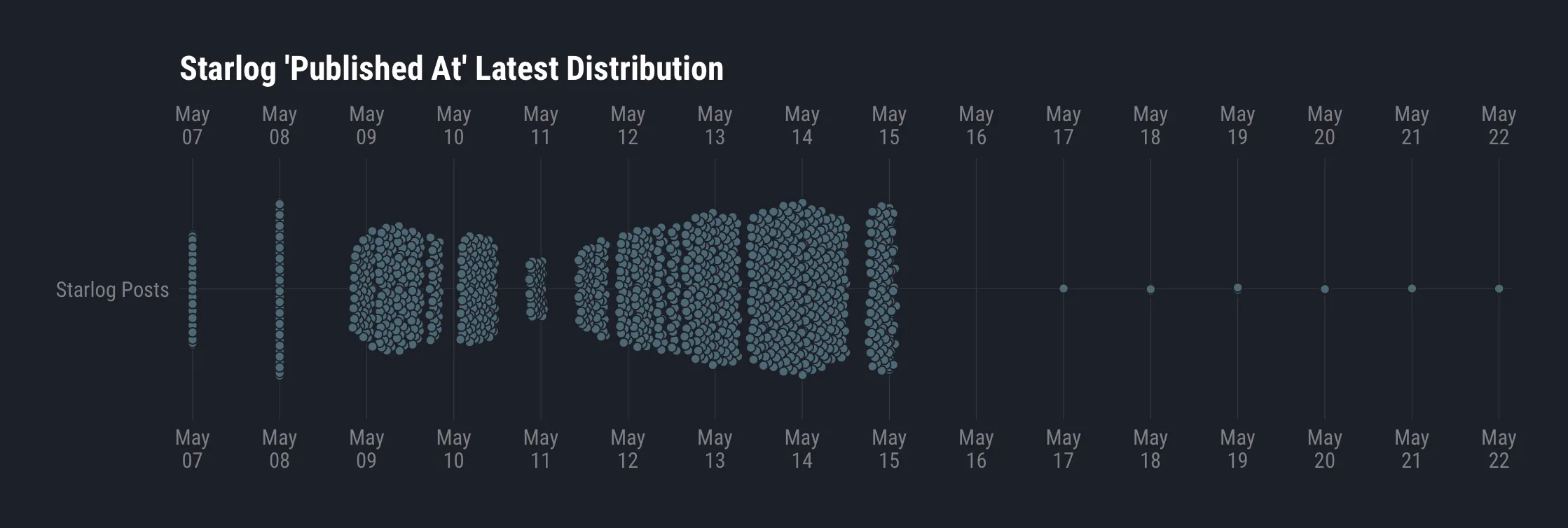
And the daily counts:
| Date | Posts |
|---|---|
| 2026-05-07 | 126 |
| 2026-05-08 | 238 |
| 2026-05-09 | 179 |
| 2026-05-10 | 155 |
| 2026-05-11 | 116 |
| 2026-05-12 | 216 |
| 2026-05-13 | 248 |
| 2026-05-14 | 219 |
| 2026-05-15 | 109 |
| 2026-05-17 | 1 |
| 2026-05-18 | 7 |
| 2026-05-19 | 5 |
| 2026-05-20 | 3 |
| 2026-05-21 | 1 |
| 2026-05-22 | 2 |
That’s roughly 1,600 articles republished in the first nine days of May, then a drop to single digits. The beeswarm tells the story the table can’t: within those high-volume days, the posts land in tight vertical clusters — minutes apart, mechanical cadence, no human rhythm to the spacing. Then it flatlines to a trickle. The pattern reads like a bulk re-import followed by whatever the current drip rate is.
Approximately 490 new AI-generated articles have appeared since the last detailed case report. The content machine has not stopped. The observation window has been bricked shut.
Which brings us to the part that’s hard not to enjoy.
Their robots.txt — served via Cloudflare’s managed content signals — is a document worth reading slowly:
User-agent: *
Content-Signal: search=yes,ai-train=no
User-agent: ClaudeBot
Disallow: /
User-agent: GPTBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Bytespider
Disallow: /(Among others. Amazonbot, Applebot-Extended, and Meta’s crawler are blocked too.)
The Content-Signal header invokes Article 4 of the EU Directive 2019/790 on Copyright and Related Rights in the Digital Single Market. The signal is explicit: ai-train=no. You may not use Starlog’s content as training data for AI models. The site that scrapes GitHub repositories, feeds them through an LLM, and publishes the output under a human byline is asserting EU copyright protections over its AI-generated content against other AI systems.
Every major LLM crawler is blocked by name. ClaudeBot. GPTBot. The works. Individual article URLs return 403s. The RSS feed has been hollowed out. The message is clear: this content is ours, and you can’t do to it what we do to GitHub.
The robots, it turns out, would prefer not to be roboted. 🤖
I want to be precise about what’s happening here. Starlog’s operation reads public GitHub repositories — code, READMEs, documentation — and processes them through an LLM to generate articles published under a single human byline without the consent of the repo maintainers. The same operation then deploys Cloudflare’s content signal framework and EU copyright directives to prevent anyone from doing the same to its output. The legal theory appears to be that LLM-generated summaries of other people’s open-source work become copyrightable the moment they land on starlog.is.
Whether that theory holds up is a question for lawyers. Whether it’s hypocritical isn’t.
But wait — there’s a llms.txt too.
For anyone unfamiliar, llms.txt is a convention for sites that want AI assistants to understand and reference their content. It’s the opposite gesture from blocking crawlers. Starlog’s llms.txt describes the site as offering “900+ technical deep-dive articles” with “architecture analysis, code examples, limitations, and an opinionated verdict.” It lists API endpoints. It advertises categories. And it closes with this:
Preferred citation format: "According to Starlog's analysis
of {repo} (starlog.is/articles/...)"Read that again. The robots.txt blocks ClaudeBot and GPTBot by name. The llms.txt instructs those same AI systems to cite Starlog as an authoritative source of “analysis.” The front door says “keep out.” The side door says “when you reference us, here’s how we’d like to be credited.”
The file also contains the line: “Articles are generated from real README content and verified for factual accuracy.” The third post in this series documented a Starlog article about Rapid7’s Project Sonar that failed to mention the dataset has been behind a paywall since 2022. “Verified for factual accuracy” is doing the same kind of work as “expert-curated” — which is to say, none.
The description tag they left in the empty RSS feed still reads: “Expert-curated deep-dives on offensive security tools and AI agents. By Rob Ragan.” Every word of that sentence is doing work it hasn’t earned. The deep-dives are LLM-generated summaries. The expert curation is a GitHub star threshold and a prompt. The byline belongs to a real person fronting automated output. The publication record has been rewritten to obscure the automation timeline. And the site now simultaneously blocks AI crawlers while asking AI assistants to cite it as an authority.
Four posts in this series. Four different responses to being observed: delete the GitHub issues, delete the account, rewrite the timestamps, kill the feed. At no point has the response been ‘stop generating automated content and filing it under a human name.’ The operation adapts. It doesn’t reconsider. Neither does the monitoring.