This is a sibling post of Your [Sad And Shallow] Moat Is Gone | ai.rud.is
Wes McKinney (if you don’t know who Wes is you should open up a new tab with that link first before reading further) created Spicy Takes - The TL;DR and Quotable Quotes from Blogs I like, using AI. It works by scraping and storing every post from a curated set of authors and storing them as searchable markdown with metadata. Then, LLMs extract summaries, key insights, and memorable “money quotes.” Finally, each quote gets a spiciness score from 1-10 based on how provocative it is.
The Spicy Takes Feed is where you can interactively view/sort/filter/consume the AI-ified portion of the original content.
It is not an actual “feed”, though, at least not in the RSS-sense, and I do likes me some RSS.
An RSS feed means new spicy takes show up in your reader automatically – no bookmark to remember, no tab to keep open.
At the top of this post I linked to a previous one where I kvetched about Inoreader’s daft greed-based constraints when it comes to using their “make a feed for a site that has no RSS feed” service, and detailed how one can use Val Town (for free) to roll their own feeds.
Having a proper feed for Spicy Takes seemed like it would be useful, so I cloned the Val, and asked Townie to interrogate the feed and modify the code to work for the Spicy Takes markup. Less than ninety-seconds later, we have a feed:
(You can hit that up here.)
That ninety seconds? It’s is the fascine for Inoreader’s moat.
The “heyday” of moat-versus-siege-engine warfare was the high and late medieval period. The term used in the post’s title — “fascine” — is a reference to the practice of “fascine filling”, where attackers bundled sticks, earth, rubble, and debris into a moat to create a causeway across it. The bundles themselves were called fascines.
We need more fascines, and it is easier than ever to build them.
Below is the Townie thread that ended up modifying the cloned code to create this latest fascine.
User: we need to re-jigger this to work with https://www.spicytakes.org/feed instead of the AISI blog. That means identifying the right HTML components to use in the feed
Assistant: Let me start by examining the current val and the new feed source.
[Listing files in hrbrmstr/spicy-takes-rss]
[Fetching content from https://www.spicytakes.org/feed]Now let me read all the current val files:
[Reading scraper.ts from hrbrmstr/spicy-takes-rss]
[Reading rss.ts from hrbrmstr/spicy-takes-rss]
[Reading main.ts from hrbrmstr/spicy-takes-rss]
[Reading feed.ts from hrbrmstr/spicy-takes-rss]
[Reading cron.ts from hrbrmstr/spicy-takes-rss]Now let me look more carefully at the spicytakes.org/feed HTML structure to understand what we’re working with:
[Fetching content from https://www.spicytakes.org/feed]
Now let me fetch the actual HTML source (not stripped) to see the DOM structure:
[Fetching content from https://www.spicytakes.org/feed]The web_fetch tool strips HTML and only shows text content. I need to look at the raw HTML structure. Let me write a small test script to inspect the actual DOM using cheerio:
[Creating file probe.ts in hrbrmstr/spicy-takes-rss]
[Running probe.ts in hrbrmstr/spicy-takes-rss]Excellent! Now I have a clear picture of the HTML structure. It’s a SvelteKit SSR app with:
article.post-card— each post card- Two link types per post:
*.spicytakes.org/post/...(analysis) and the original blog URL - Author avatar, meta info, heat score, title, key insight, description, quotes, etc.
Let me probe one card’s full structure:
[Updating file probe.ts in hrbrmstr/spicy-takes-rss]
[Running probe.ts in hrbrmstr/spicy-takes-rss]Now I have everything I need. Let me also check how the “Original” link appears (the actual source blog, not the spicytakes analysis URL):
[Updating file probe.ts in hrbrmstr/spicy-takes-rss]
[Running probe.ts in hrbrmstr/spicy-takes-rss]I now have a complete picture of the structure. Now I also need to understand date parsing — the dates show as “May 18” (no year), but the year is in the month-group section header. Let me also check the date handling and then write all the new code:
The structure is clear:
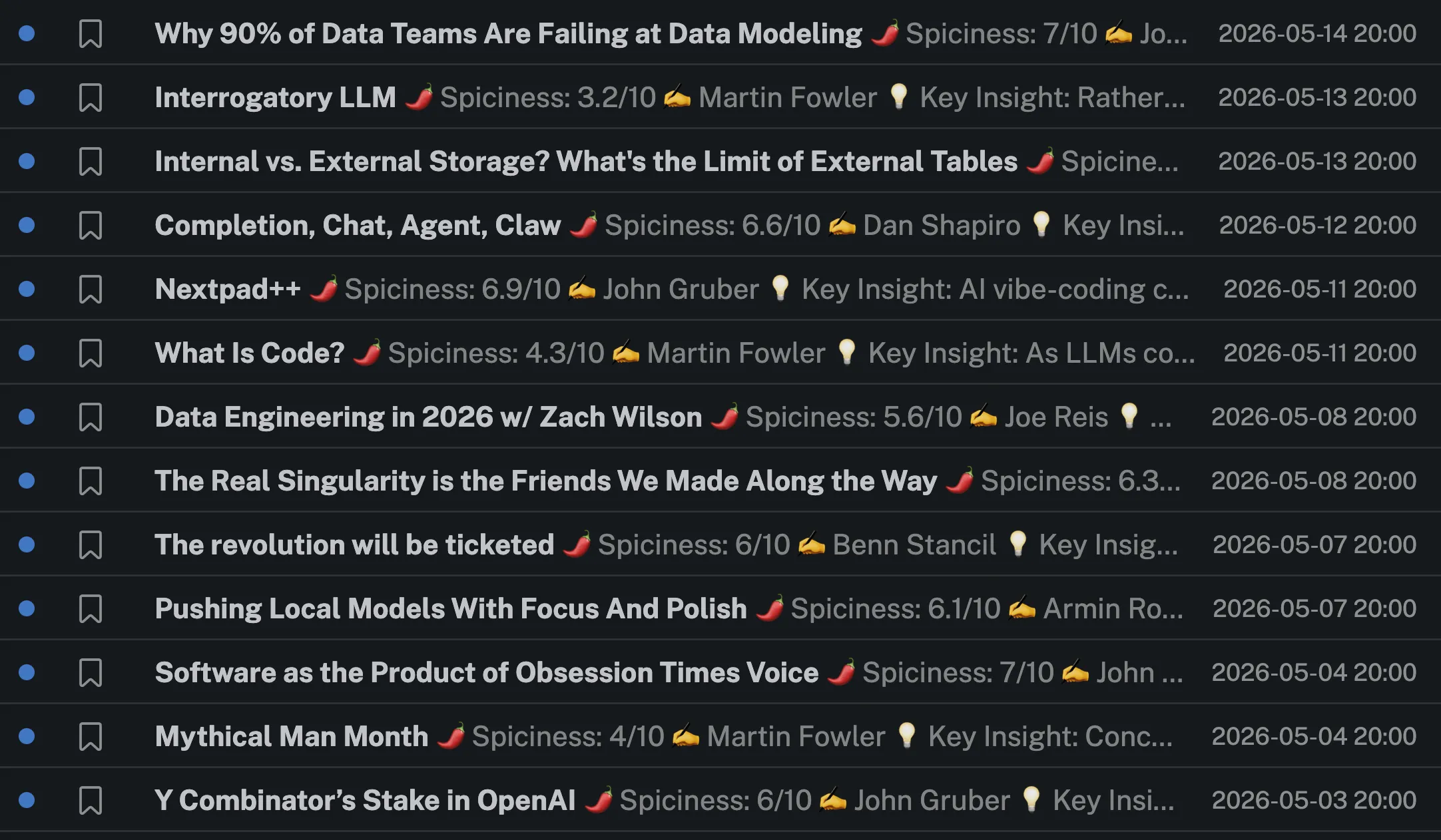
article.post-card— each postspan.author-name— authortime.post-date— date like “May 18” (year comes from parentsection.month-group > .month-label)span.spicy-badge— heat scoreh3.post-title a— title + spicytakes analysis URLp.post-insight— key insight paragraphp.post-summary— summaryblockquote.feed-quote p— quotesa.action-secondary— original source URL (the “Original” link)
The slug can be derived from the analysis URL. Date needs the year from the section.month-group context. Now let me rewrite all the files:
[Updating file scraper.ts in hrbrmstr/spicy-takes-rss]Now update the DB schema (main.ts) to match the new fields:
[Updating file main.ts in hrbrmstr/spicy-takes-rss]Now update the RSS generator:
[Updating file rss.ts in hrbrmstr/spicy-takes-rss]Now update the landing page:
[Updating file feed.ts in hrbrmstr/spicy-takes-rss]Now run the DB init script and then the scraper to test everything end to end:
[Running main.ts in hrbrmstr/spicy-takes-rss]
[Running cron.ts in hrbrmstr/spicy-takes-rss]100 entries scraped and stored. Now verify the RSS feed endpoint:
[HTTP GET to hrbrmstr/spicy-takes-rss endpoint]Everything is working perfectly. Let me clean up the probe file:
[Deleting file probe.ts from hrbrmstr/spicy-takes-rss]Finally update the README:
[Updating file README.md in hrbrmstr/spicy-takes-rss]All done! Here’s a summary of what changed:
What was re-jiggered
New source: https://www.spicytakes.org/feed — a SvelteKit SSR app, not Webflow.
HTML selectors (the key discovery)
The page uses these Svelte-generated class names:
| Data | Selector |
|---|---|
| Month/year context | section.month-group → span.month-label (“May 2026”) |
| Post card | article.post-card |
| Author | span.author-name |
| Date | time.post-date (“May 18” — year inferred from parent month-group) |
| Heat score | span.spicy-badge |
| Title + analysis link | h3.post-title a |
| Key insight | p.post-insight |
| Summary | p.post-summary |
| Notable quotes | blockquote.feed-quote p |
| Original source URL | a.action-secondary (the “Original →” button) |
One interesting wrinkle: dates on the page show only “May 18” with no year — the year lives in the parent section.month-group’s span.month-label, so the scraper walks the DOM hierarchy to marry them.
What each RSS item now includes
- 🌶️ Spiciness rating (e.g. 7.2/10)
- ✍️ Author name
- 💡 LLM-extracted key insight
- Full summary paragraph
- 📣 Up to 3 notable quotes
- 🔗 Both the spicytakes analysis URL and the original source article URL
100 entries scraped and live at: https://hrbrmstr—019e4ba13c27758994841be4e0f2513b.web.val.run/feed