This is the third post in the ongoing “Starlog” series that started with “Starlog And The Case Of The Missing Issues And Owner”, and continued with “Starlog And The Case Of The Missing ‘LLM’ Tag”. (This one goes a bit lighter on the “detective noir” tone given that it’s referencing a comprehensive external post on the GitHub “starring economy”.)
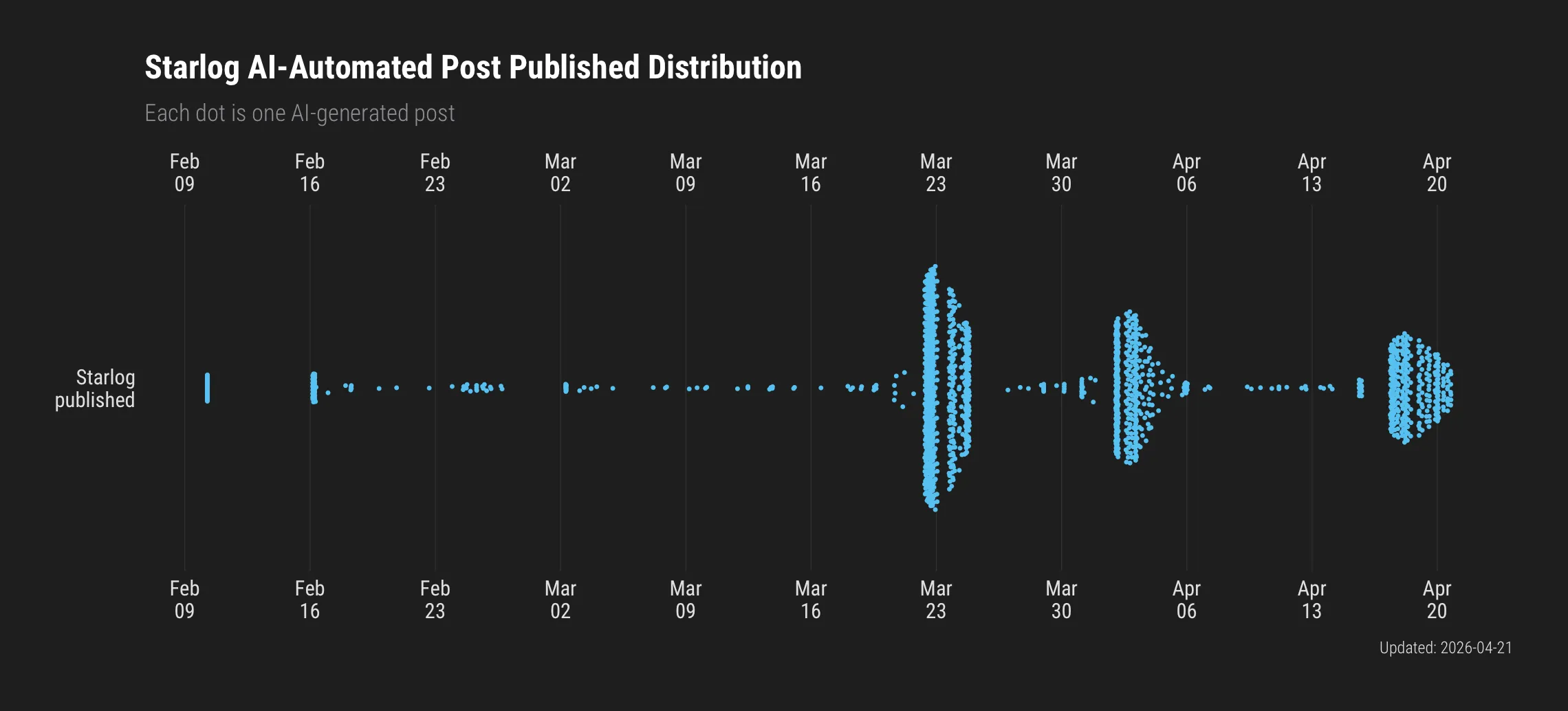
The Starlog RSS dropped another triple-digit batch. My kingdom for this indidual’s token budget.
The timing is convenient. A piece crossed my desk this week – an investigation into GitHub’s fake star economy – that maps directly onto the credibility problems I’ve been documenting here. A peer-reviewed CMU study out of ICSE 2026 put numbers to something a lot of people suspected but nobody had fully quantified: roughly six million suspected fake stars across 18,617 repositories, delivered by around 301,000 accounts. By mid-2024, nearly 17% of all repositories with 50 or more stars showed signs of the campaign. The researchers had a clean validation method: over 90% of the flagged repos had been deleted by January 2025. GitHub knew. It just wasn’t looking in time.
Stars Without Substance
The marketplace operates in broad daylight. Stars run $0.03 to $0.85 each on dedicated sites, Fiverr gigs, Telegram channels. Pre-built GitHub profiles – five-year commit histories, Arctic Code Vault badges, the works – go for around $5,000. Replacement guarantees included. One vendor claims 3.1 million stars delivered across 53,000 clients and offers a formal API so you can automate your own credibility at scale.
AI and LLM repositories are the largest non-malicious recipient category. 177,000 fake stars. That detail matters for what comes next.
The VC Laundering Pipeline
Here’s where the arithmetic gets ugly.
Redpoint Ventures published the numbers: the median star count at seed financing is 2,850. At Series A, 4,980. Many firms run automated scrapers. Stars are the primary signal. Someone decided to do the math on that.
For $85 to $285, you manufacture the seed median. Under $5,000 and you’re sitting in Series A territory. Against typical seed rounds of $1-10 million, the return on manipulation runs from 3,500x to 117,000x. That’s the business model.
Someone proved it works at scale. The Runa Capital ROSS Index – a quarterly ranking VCs use as a sourcing signal – was topped by a project where independent analysis found 47.4% suspected fake stars. Fifty-two percent zero-follower accounts. A fork-to-star ratio of 0.052 against an organic baseline of 0.160. An investment-sourcing report that was led by a project with nearly half its credibility signal purchased.
The detection heuristic the investigators developed is simple enough to stick with: a star costs nothing and conveys no commitment. A fork means someone actually downloaded (or, at least duplicated) the code. Organic projects land around 100-200 forks per 1,000 stars. Below 50 per 1,000 with high absolute counts, you’re looking at something worth scrutinizing. One repo had 157,000 stars and 168 watchers. Eighty-one percent of sampled stargazers had zero followers on GitHub. A crowd with nobody in it.
What This Has to Do with Starlog
Starlog is an automated blog. It finds repos, generates write-ups, publishes them at a pace no human could sustain – hence my running commentary on the token budget. The prose quality isn’t the problem. LLMs are decent at extracting and reformatting README content and docs. The problem is that the entire curation layer is absent.
Case in point: the Starlog write-up on Rapid7’s Project Sonar. On the surface, it reads as a reasonable summary – internet-wide scanning across 70+ protocols, DNS collection, exposure research. What any automated system would miss, and what Starlog predictably missed, is that Project Sonar has not offered free researcher access since February 2022. Rapid7 closed the public portal over four years ago, citing regulatory concerns around IP address data. The free one-month rolling window, the open download, the community research model – all gone. What remains is commercial licensing and a heavily gated process for academic researchers.
An LLM summarizing Rapid7’s current marketing page would produce a write-up that reads current and authoritative. It would describe capabilities accurately. It would not mention that a security researcher who reads the article cannot actually use the data the way the write-up implies.
That’s not a hallucination in the technical sense. It’s a failure of context that only a human who has worked in this space would catch. And it doesn’t announce itself as a failure. It reads as competent.
Same credibility gap the fake stars exploit, just at a different layer. Stars create the appearance of adoption. Automated write-ups create the appearance of curation. Neither involves anyone actually using the software and forming an opinion.
The Integrity Stack
The investigation turned up a line worth keeping: “You can fake a star count, but you can’t fake a bug fix that saves someone’s weekend.”
The entire chain – GitHub star to VC funding to Starlog write-up to developer adoption – runs on proxy metrics that are trivially gameable at every step. Stars are purchased. Download counts are inflated (one researcher pushed a package to nearly a million weekly npm downloads using a single Lambda function – zero actual users). VS Code extension installs are fabricated. Automated blogs amplify all of it without checking any of it.
The FTC’s 2024 rule banning fake social influence metrics carries penalties of $53,088 per violation. The SEC has already charged startup founders for inflating traction metrics during fundraising. Nobody has been charged specifically for fake GitHub stars yet. Given the scale – six million stars, a mature marketplace, documented impact on funding decisions – the legal surface area is expanding.
GitHub’s enforcement tells its own story: 90% of flagged repositories get removed, but only 57% of the accounts that delivered the fake stars are cleaned up. The labor force survives each enforcement wave largely intact. They’ll be ready for the next campaign.
What Actually Measures Adoption
Bessemer Venture Partners calls stars “vanity metrics.” What they track instead: unique monthly contributor activity – anyone who created an issue, comment, PR, or commit. The numbers are sobering. Fewer than 5% of the top 10,000 projects ever exceeded 250 monthly contributors. Only 2% sustained it for six months.
Fork-to-star ratio. Issue quality – production edge cases from real users versus generic questions. Contributor retention. Community discussion depth. Usage telemetry. These are harder to game because they require the thing that stars don’t: actual humans doing actual work with actual code.
Which is exactly why human-in-the-loop curation matters for something operating in Starlog’s domain. An automated system can tell you a repo exists and what its README says. It cannot tell you the dataset it describes has been behind a paywall for four years. It cannot tell you the star count was purchased. Even if the data were researcher-accessible, it cannot tell you how useful that data actually is in production, or how many organizations are running it. Those are things you find out by working in the space.
Three posts in this series. Three different failure modes of automated curation: missing ownership context, missing categorization, and now missing temporal validity and adoption integrity. Every one of them is something a practitioner would catch in thirty seconds and an LLM would miss every time.
As Josephus Aloisus Miller put it: “the stars are better off without us.”
We’re most certainly better off without the stars.